Distributed Computing
When a computational task is highly parallelizable, a computational completion time speedup can be obtained by parallelizing across GPUs or CPUs. GPUs are cheap and abundant- however, there are limitations on what kinds of algorithms and code can be used on a GPU thread. For example, one thing I ran into, trying software such as Thrust and Kokkos, to have a single GPU thread sort an array in C++. Developers of Kokkos at Los Alamitos Laboratory confirmed this could not be done. So, despite the accessibility for GPU clusters, what if a CPU cluster is needed? For many applications (large-scale computations, including those from Blackjack or other parallelizable problems), I use a computing cluster of my own to complete computational tasks.
Hardware
One would want to scale the number of nodes to as large as one needs. Power consumption for the cluster (and also for cooling) are considerations for what the hardware limit would be for an environment. Outlets can spread across multiple circuits of a circuit breaker of a facility/office. A diagram describing my cluster framework is as follows:
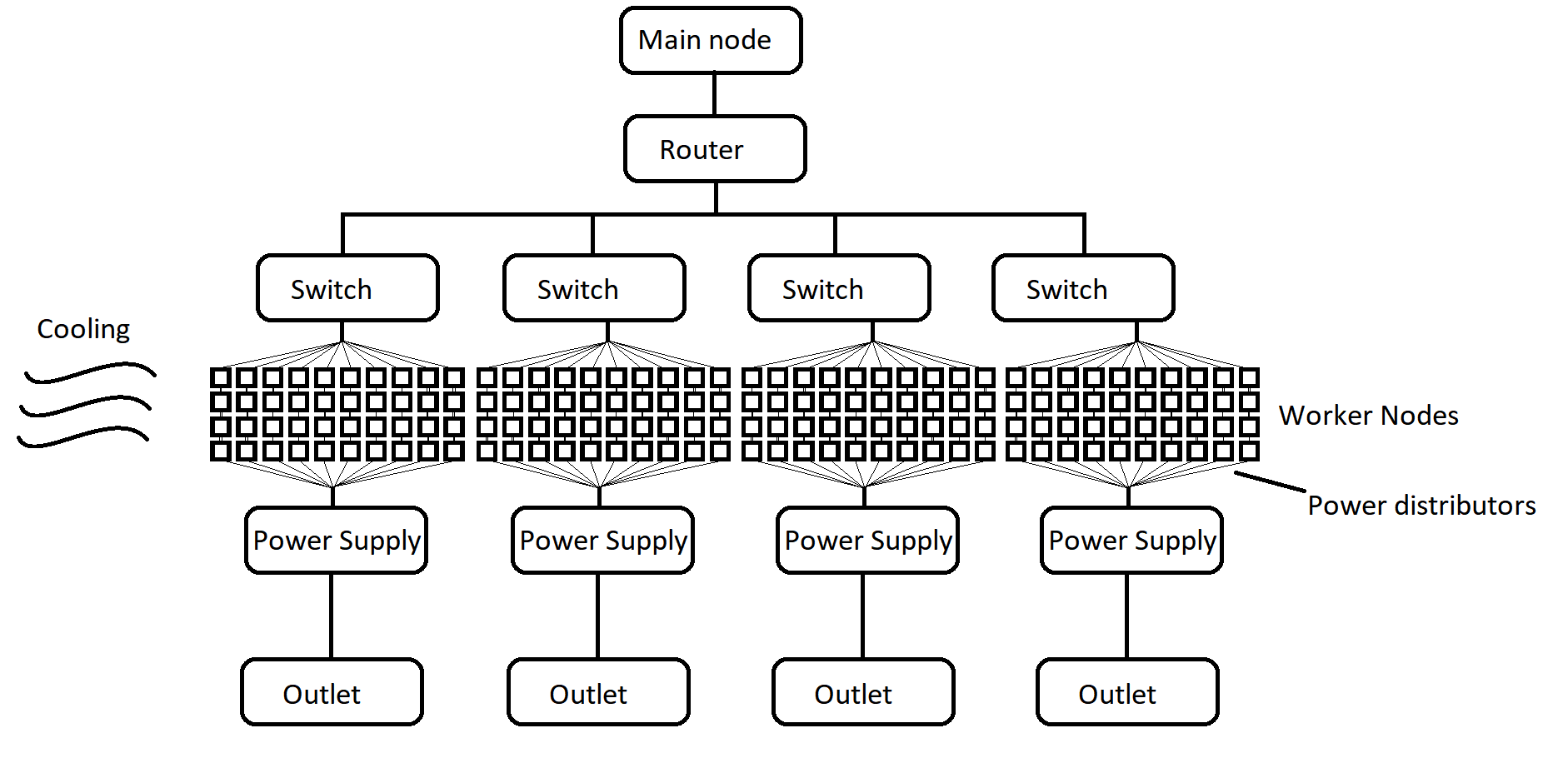
Ideally, each node is energy efficient and is able to stay cool. From experience, if not enough current is provided to a node, or if not enough air circulation is provided to keep any of the CPUs cool, computations of the entire cluster slow to a halt or the node is not recognized by the router / main machine. One must consider that even though enough power is used to turn on a node, more power (I've seen 2x) is required for when a computation is running, compared to idle.
For float precision, to calculate FLOPS of my current cluster (2022),
\[ \text{FLOPS} = \left(\text{nodes}\right)\left(\frac{\text{cores}}{\text{node}}\right)\left(\frac{\text{cycles}}{\text{second}}\right)\left(\frac{\text{FLOPs}}{\text{cycle}}\right) \approx 14\times10^{12} \text{ FLOPs} = 14 \text{ teraflops} \]
For double precision, the same calculation leads to \(\approx 7 \text{ teraflops}\). This is approximately the equivalent of the world's fastest supercomputer in the year 2000, but the speed of supercomputers are currently growing exponentially every year.
Software: MPI
MPICH (from Argonne National Laboratory) is used, to help communicate data from a main node to worker nodes. There are tutorials online about MPI documentation, and below are what I find particularly useful functions for gathering (scattering) data from (to) worker nodes to (from) the main node.
#include <stdio.h>
#include "mpi.h"
#include <iostream>
int main()
{
int isend, irecv[3];
int rank, size;
MPI_Init();
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
isend = rank + 1;
MPI_Gather(&isend, 1, MPI_INT, &irecv, 1, MPI_INT, 0, MPI_COMM_WORLD);
if(rank == 0)
{
cout << "irecv[0] = " << irecv[0] << "; irecv[1]= " << irecv[1] << "; irecv[2]= " << irecv[2] << endl;
}
MPI_Finalize();
return 0;
}
#include <stdio.h>
#include "mpi.h"
#include <iostream>
int main()
{
int isend[3], irecv;
int rank, size, i;
MPI_Init();
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
if(rank == 0)
{
for(i=0;i<size;i++)
{
isend[i] = i+1;
}
}
MPI_Scatter(&isend, 1, MPI_INT, &irecv, 1, MPI_INT, 0, MPI_COMM_WORLD);
cout << "rank = " << rank << "; irecv= " << irecv << endl;
MPI_Finalize();
return 0;
}
Alternatives to MPI include Spark to be run using a AWS cluster or Azure cluster. Factors to consider: one has less control over the nodes of a AWS or Azure cluster, as one node can go down and the cluster will remain operating, and Spark handles this. Using MPI, one has full control of which computations are run on which node, for a predetermined \(N\) nodes for a calculation. Also, if one is running a large-scale numerical optimization where the cluster will be run nonstop for weeks or months, it may be cost-effective to have an in-house hardware solution rather than renting out cloud computing (one can perform this cost-benefit analysis). Using MPI, one primarily uses C/C++ which is likely the fastest language for a Machine Learning calculation, whereas Spark primarily deals with Python/R/Scala (which are slower than C++) but it is possible using Cython using Spark.